☰
The gap between commercial and open-source LLMs for Olympiad-level math is shrinking
OpenAI’s o3 vs AIMO2’s first and second-placed teams, NemoSkills and imagination-research, and the combined power of all AIMO2 participants.
AIMO and OpenAI have collaborated to run an experiment applying an unreleased version of OpenAI’s o3 model, o3-preview, to the 50 unreleased Olympiad-level math problems from the public leaderboard of AIMO Progress Prize 2.
We compare the performance of o3-preview, a generalist model, to the first and second-placed model submissions in the open-source AIMO Progress Prize 2 competition that were optimized for mathematical performance: (1st) NemoSkills, a team of researchers from Nvidia; and (2nd) imagination-research, a team of students, professors, and researchers from Tsinghua University and Microsoft Research, as well as to the "AIMO2-combined", the combined performance of all AIMO2 teams.
These 50 problems were newly created and unseen by any of the evaluated models, making this one of the largest contamination-free, robust evaluations of challenging math problems to date.
By Simon Frieder, AIMO Prize Manager
Introduction
The Artificial Intelligence Mathematical Olympiad (AIMO) was created in 2023 to foster the development of open-source AI models capable of advanced mathematical reasoning. The Grand Prize of $5mn will be awarded to the first publicly shared AI model that can achieve a standard equivalent to a gold medal at the International Mathematical Olympiad.
The AIMO Progress Prize 2 (AIMO2), which concluded in April 2025, was hosted on the Kaggle platform, which provided the essential infrastructure for the competition. This stage saw the difficulty of the problems increase and centre around the national olympiad level, such as BMO (British Mathematical Olympiad) or the USAMO (United States of America Mathematical Olympiad).
It was a closely fought stage, with more teams achieving higher scores than in AIMO Progress Prize 1 (AIMO1). While the highest score on AIMO1 was 29/50 on the private leaderboard, AIMO2 saw an increase in winning score to 34/50 on the private leaderboard. Compared to AIMO1, a total of seven teams achieved more than 29/50 points in AIMO2 on the private leaderboard.
We note that all Kaggle competitions utilise two leaderboards: A public one and a private one, with problems being approximately equally distributed among both. Perhaps a misnomer, the "public leaderboard" on Kaggle, which we used as our present eval set, does not mean that our problems were publicly available. In fact, we took great care to keep all our problems, from both the public and the private leaderboard, completely hidden, thereby avoiding the contamination of any language model with them. The "public" leaderboard on Kaggle is the leaderboard that is visible throughout the lifetime of a competition. Because repeated evaluation in a single leaderboard, even if its problems remain hidden, might indirectly leak information, Kaggle uses a second, private leaderboard with similar problems, on which models are evaluated only once, to assess the winners of a competition. Small deviations due to the stochastic nature of the models are possible.
The top five winning teams of AIMO2 and their scores on the private leaderboard are below (with public leaderboard scores given in parentheses):
- NemoSkills: 34/50 (public leaderboard: 33/50)
- imagination-research: 31/50 (public leaderboard: 34/50)
- Aliev: 30/50 (public leaderboard: 28/50)
- sravn: 29/50 (public leaderboard: 25/50)
- usernam: 29/50 (public leaderboard: 25/50)
This is an impressive achievement, considering the significant increase in problem difficulty compared to AIMO1. It is great to see that the AIMO series of competitions is fast becoming a benchmark competition, encouraging the proliferation of open-source AI models for mathematical reasoning.
However, a fascinating question remained unanswered: How would closed AI models perform when unleashed on AIMO’s competition problems? We decided to take a look.
To assess the gap between open-source LLMs and state-of-the-art commercial LLMs, which currently have superior reasoning performance, we ran three special evaluations with OpenAI, NemoSkills, and imagination-research on our 50 problems that made up the AIMO2 public leaderboard. As part of the open-source requirements of the AIMO Prize, there are detailed, technical write-ups available online for all winning models, including both the NemoSkills’ model and the imagination-research model.
Furthermore, we compared these results with those of "AIMO2-combined", defined as the collective performance of the best models from all 2k+ Kaggle participating teams, counting a problem as solved if at least one of the models solved it. In the next three sections, we will first outline the performance of o3-preview, followed by the performance of the first and second-placed teams, and the performance of AIMO2-combined.
o3-preview
Towards the end of the AIMO2 competition, in March, we ran the 50 problems from the AIMO2 public leaderboard through the nominated o3-preview model, which is the same version that was used for the ARC-AGI challenge, using several model versions. This is a generalist model that is not optimized solely for mathematical performance, unlike the AIMO2 models, and is able to handle arbitrary reasoning tasks.
To ensure that the AIMO2 problems from the public leaderboard stay hidden, we engaged with OpenAI to obtain access to a machine that guarantees that carrying out this evaluation will not leak any of our problems and will, in particular, not lead to contaminating their training data in any way, thus preserving these problems as uncontaminated, challenging Olympiad-level problems for future use.
We ran o3-preview on three different parameter settings, low-, medium-, and high-compute, which influenced both the internal thinking and reasoning level with which o3-preview performed, and led to varying hardware costs. We note that the low-compute and medium-compute versions conceptually correspond to a base model that was run with two different parameter settings, while the high-compute version additionally uses a learned scoring function to pick its best answers. This form of sample-and-rank mechanism, fixed at a certain sampling rate, delivers improved performance.
As with the Kaggle competition, the test was run under strict conditions, ensuring that the public test set remained uncontaminated and no data was leaked. Each test involved only one attempt at finding a solution. While the low-compute and medium-compute versions correspondingly returned one answer, the high-compute version of o3-preview, employing the sample-and-rank mechanism under the hood, returned several answers, together with a score.
The scores of the OpenAI model, depending on its compute version, are:
- o3-preview (high-compute version, counting both top-ranked and second-ranked answers): 50/50
- o3-preview (high-compute version, counting only top-ranked answers): 47/50
- o3-preview (medium-compute version): 46/50
- o3-preview (low-compute version): 43/50
The low-compute version of o3-preview solved seven points more than NemoSkills' winning AIMO2 model when it was run on stronger hardware than on Kaggle (see below). Information about the hardware on which o3-preview ran was not available to us. The medium-compute version solved the same problems that the low-compute version solved, plus an additional three, totalling 46/50.
The high-compute version, achieving 47/50 when counting only the top-ranked answers and 50/50 when counting also second-ranked answers, shows that the o3-preview model, in principle, has the ability to produce correct answers to all of our 50 problems.
This is comparable to the combined score of the best-performing models of all 2k+ participating Kaggle teams in AIMO2, AIMO2-combined, who managed to also solve 47/50 problems in total, though we note that care has to be taken when reporting and comparing scores.
The 47/50 score that AIMO2-combined obtained (for more information, see the section below) is approximately similar to a "pass@2k+"-type score, meaning that among the 2k+ attempts per problem, at least one solution was correct, and no other ranking is performed. More generally, the commonly used scores of the "pass@n"-type refer to some (fixed black-box) model, which is queried n times and the correct solution is counted among the n outputs, and that is then reported (even if the model internally can do many more runs). No model state is allowed to be retained between the runs. Of course, the 2k+ model submissions are all different and, strictly speaking, pass@n scores require the same underlying model, so pass@2k+ is an approximate score. For more information about this type of score, we refer to the original definition of this metric in the SPoC paper, as well as to this blog by the author. The scores from the o3-preview low-compute, o3-preview medium-compute, and the 47/50 score for o3-preview high-compute are pass@1-type scores.
Across the three levels, the seven math problems that o3-preview’s low-compute version did not solve comprised two geometry problems, two algebra problems, and three combinatorics problems. While o3-preview performed very strongly, there was one particular problem that stood out, called "RUNNER" (see the graphs below), that was solved by NemoSkills, but not by o3-preview low-compute or medium-compute, and whose correct answer was only second-ranked by o3-preview high-compute. Conversely, another problem, "EIGHTS", was solved by o3-preview high-compute as top-ranked answer, by none of the top-five AIMO2 models, but by several of the other, lower-ranking AIMO2 models.
The large number of problems that were used, combined with their difficulty (most were at a level of a national math Olympiad, with some problems slightly easier and some problems slightly harder, approach IMO-level of difficulty), the fact that the evaluation of all o3-preview models took place over a very short timeframe, several hours, and access was given to the raw API outputs, makes our evaluation of o3-preview very robust. We have a lot of confidence that these results represent a milestone for AI-based reasoning on very challenging domains.
NemoSkills and imagination-research
In a separate experiment, we worked with NemoSkills and imagination-research to further evaluate their models’ full potential by using better hardware and enabling longer runtime. The respective teams were granted access to a private machine comprising 8x H100 GPUs, installed their model, and made sure the model performed well by testing it on their own problems or publicly available problems, such as the AIMO2 reference problems. Once the models were running, access to the teams was removed, and we ran the evaluation. This ensured, analogously to o3-preview, that our 50 challenging problems from the public leaderboard stayed hidden, and no information about the problems was leaked at any time.
In AIMO2, restrictions on participating teams were imposed so their models would run on the Kaggle platform, which made available four L4 GPUs with a combined 96 GB of VRAM per team. For the current evaluations, we allowed the model to apply its full power to the 50 public leaderboard problems by removing model tweaks that teams made to ensure the model was able to run on the Kaggle platform. We worked with the NemoSkills and imagination-research teams while they had access to the 8x H100 machine to strip out all timeout mechanisms and other time-management code and increase precision and context-window size, among other minor changes that improve performance. The number of parameters, as well as core model logic, including any prompt engineering, model fine-tuning, etc., remained unchanged compared to the model that ran on Kaggle.
We subsequently re-ran NemoSkills’s model and imagination-research’s model on the 50 problems on a machine comprising eight H100 GPUs, totalling 640GB of memory. NemoSkills scored 35/50, up from 33/50 on the Kaggle public leaderboard, and imagination-research also scored 35/50, up from 34/50 on the Kaggle public leaderboard (all of these are pass@1 scores, too). These unrestricted and slightly augmented versions of the models will also be released publicly. Evaluations each took less than a day, and thus didn't test the limits of our 8x H100 machine. Analogous models with larger parameter sizes may perform better.
AIMO2-combined
To put the previous results in context, we have plotted two graphs (each showing 50 problems, split into two columns) that contrast the performance of each o3-preview version (we used only the top-scoring answers only for the high-compute version of o3-preview), as well as of each of the original, Kaggle-restricted winning models with the overall performance of AIMO2-combined, i.e., the performance on our 50 problems of the best-performing submitted models among all submitted models per team, across all participating teams. AIMO2-combined solved 47/50 problems, the same score that the high-compute version of o3-preview achieved when counting top-scoring answers only. Technical caveats regarding the result of AIMO2-combined are outlined below.
First, we show the graph that compares o3-preview with the original Kaggle version of NemoSkills—omitting the unrestricted variant that, as noted above, achieved slightly higher scores. Its y-axes display the individual problems, and its x-axes display percentages (explained below), and it shows how well o3-preview and NemoSkills performed on the 50 problems from the public leaderboard compared to the highest-scoring model submissions of AIMO2-combined.
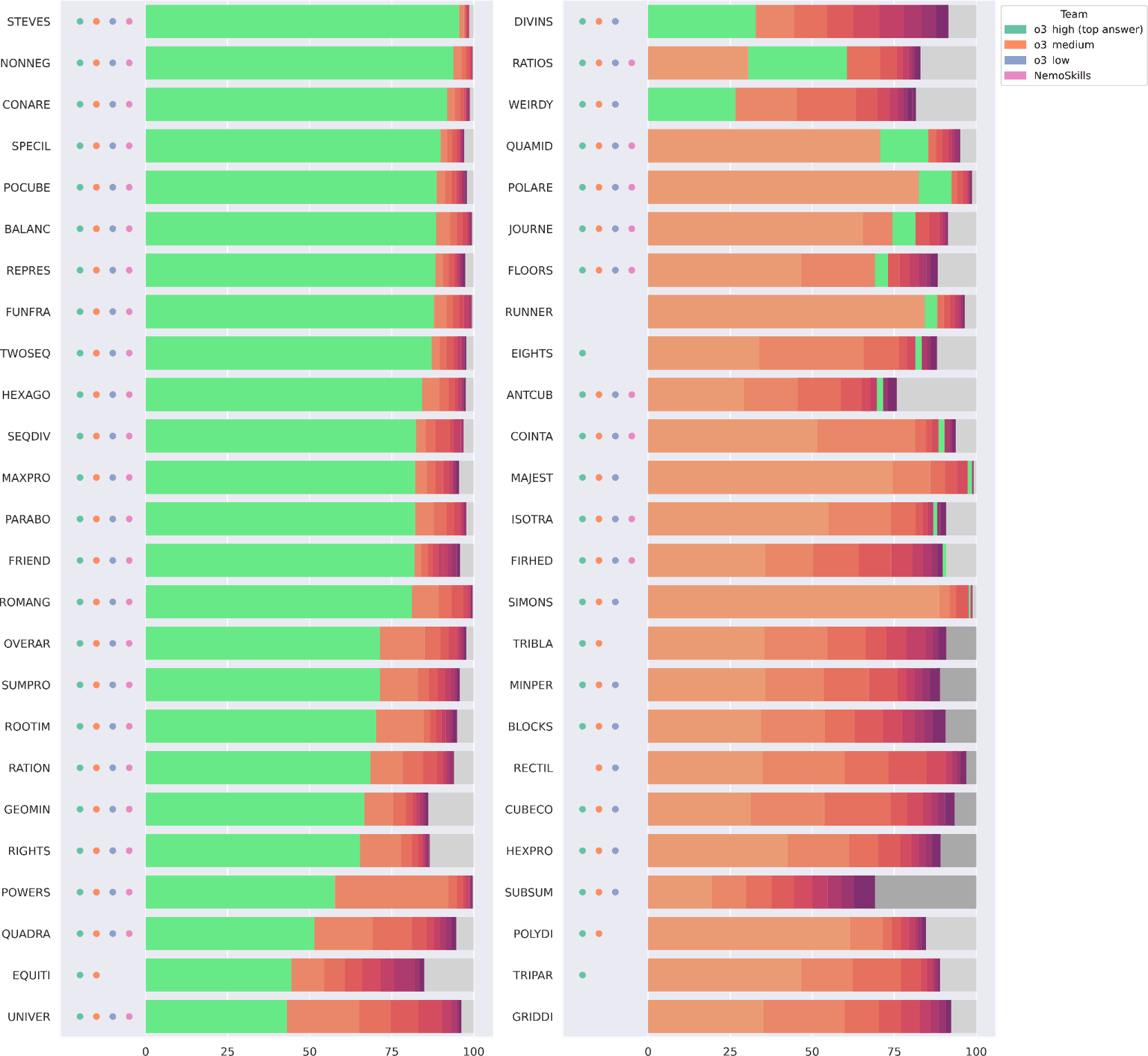
The AIMO2-combined data—used to generate these graphs—was collected as follows: If there were model submissions achieving identical top scores (e.g., if a participating team submitted the same-scoring model at multiple dates or if a participating team's submission achieved the same overall score but solved different problems each time), we broke ties by taking the latest highest-scoring model submission. Other tie-breaking mechanisms could be used, but they would change the graph only minimally. The top submissions of the team were typically made towards the end of the competition, although we placed no restriction on when the top submission had to be made.
Each problem on a y-axis is represented by a textual label, a sequence of dots, and, from left to right, a sequence of eleven bars: Ten coloured bars with an eleventh gray bar at the end. The problems are ordered in decreasing manner depending on how many Kaggle teams solved them: The left column denotes the 25-most solved problems from top to bottom, and the right column denotes the 25-least solved problems. For each problem, the sequence of up to four dots indicates which of the four models listed in the legend solved that problem. E.g., the "GRIDDI" problem was not solved by any of the four models.
The horizontal sequence of first ten coloured bars, starting from the left, represents the ten most frequently given numeric answers across AIMO2-combined, where the length of the bar corresponds to the percentage that describes how many of the top submissions we considered for this graph generated that particular answer; the ten colours, ranging from orange to purple, indicate that each of these ten most frequent numeric were incorrect. If one of these ten bars is coloured green, it means that the answer was the correct one.
For example, for the "POLARE" problems, this means that the second-most frequent answer out of all top submissions was the correct one (and all four models, o3-preview in its three versions and NemoSkills, got that answer right, too), while for the "FRIEND" problem, the most frequent answer was the correct one (which was again solved by all four models).
We note that for some problems, such as "MAJEST", out of the ten most frequent answers, the ones towards the tail end in terms of frequency are sufficiently small in relative numbers so that the bars are hard to visually distinguish. The green bar with the correct answer can be made out, but the bars representing the ninth and tenth most frequent answers cannot. For the "SIMONS" problem, the tail of the most frequent answers is also very short, indicating that most submissions are concentrating around a few answers, while "SUBSUM" has the longest tail, suggesting that there was the most uncertainty here among all model submissions.
The eleventh bar at the end lumps together, in percentages, the submissions that generated all other answers outside the top-ten most frequent ones. That bar is dark gray if the correct answer is among those answers, and light gray otherwise. This means if a green bar is displayed for a given problem, a dark bar cannot occur at the same time (and vice versa), as there cannot be two distinct answers that are both correct. We can observe that for a total of three problems, "POLYDI", "TRIPAR", and "GRIDDI", neither green nor dark gray bars are present, indicating that none of the models submitted by any participating Kaggle team were able to solve them. AIMO2-combined thus solves, as indicated earlier, 47/50 problems, rivalling o3-preview high-compute.
We note that the problems whose gray bars are dark are ordered in descending manner according to the relative proportion of how many of the "gray-bar" submissions (i.e., submissions outside of the ones generating the top-ten most frequent answers) gave the correct answer. E.g., for the "TRIBLA" problem, approximately 9% of the gray-bar submissions got the correct answer. In terms of total percentages, these were slightly below 1% of all submissions. The problems without any submission generating the correct answer, whose eleventh bar is light gray, are displayed in decreasing order of their most frequent answer (which corresponds to the bright orange bar). While this is a spectacular achievement, there are some caveats regarding the comparison of AIMO2-combined with o3-preview. Due to the large number of top submissions that produced answers, it is possible that some answers were guessed, rather than obtained by reasoning. We will investigate this in more detail in an upcoming technical report in order to disambiguate better which of the correct answers were guessed and which relied on reasoning. On the other hand, AIMO2-combined, over the lifetime of the AIMO2 competition, used in total significantly more computing power than the models by NemoSkills and imagination-research, which were run on an 8x H100 machine in a day.
The next graph below has the same structure and compares the top-five scoring models on AIMO2 with each other, to complete the picture; both NemoSkills’ model and imagination-research’s model are in their original, Kaggle-restricted versions. We repeat the bars that summarize the performance of the Kaggle competitors to allow easy comparison with the five winning model represented as dots. On the public leaderboard—not used to determine winners— imagination-research ranked slightly higher than NemoSkills, which below illustrates just how narrow the margin was between the two models in the final standings.
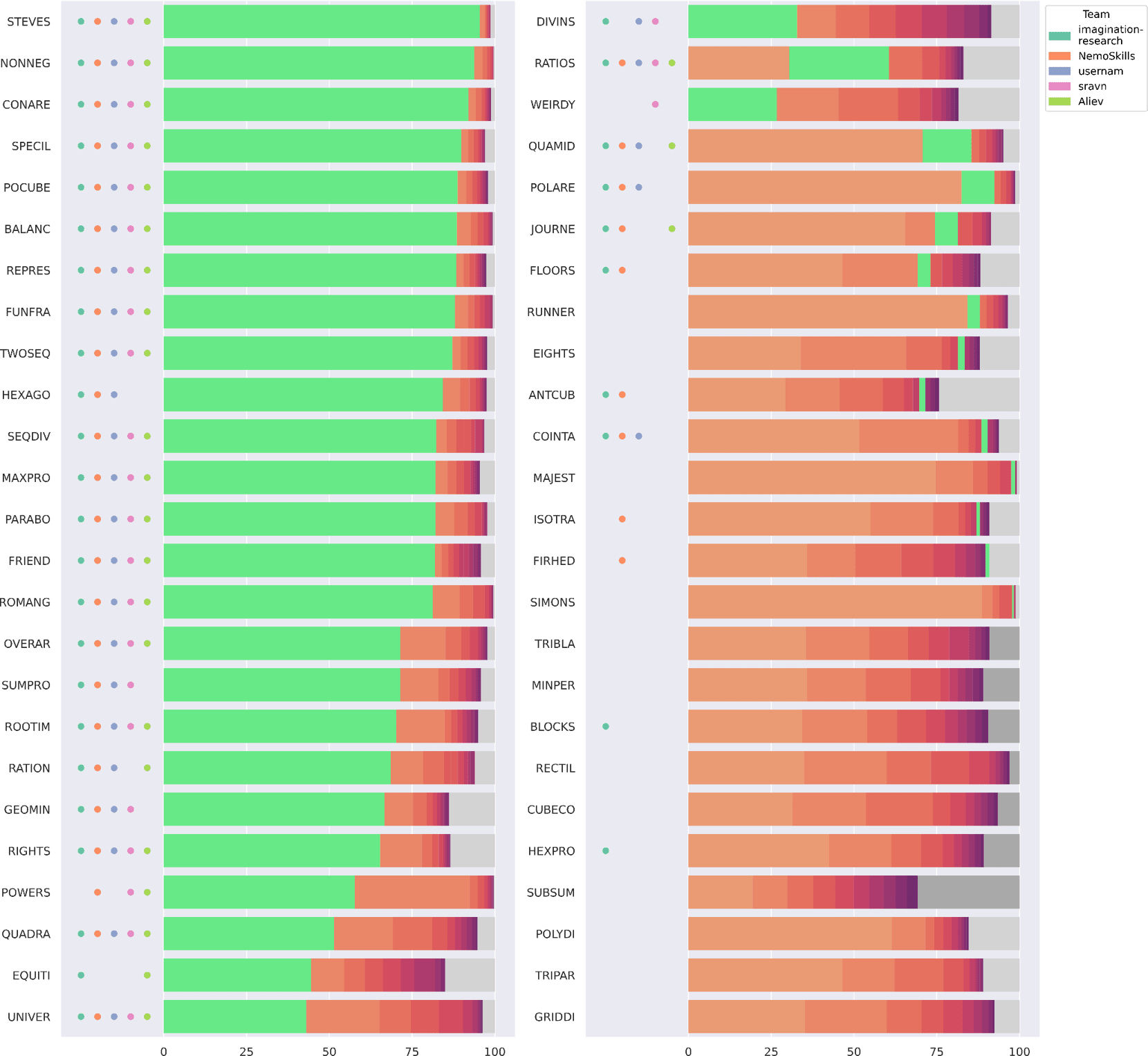
Taken together, these two graphs illustrate how wide the performance gap is between state-of-the-art LLMs (both commercial and open-source). Notable takeaway points are the following:
-
o3-preview is a very strong model, solving some of the problems, such as "TRIPAR" or "POLYDI" that none of the Kaggle teams (including the winners) were able to solve.
-
The NemoSkills and imagination-research models are currently the best open-weight models in terms of performance on challenging math problems, significantly beating the foundation models on which they rely. They are both very similar in terms of performance, although they employ different approaches to reach this level of reasoning proficiency.
-
AIMO2-combined has formidable reasoning power in terms of deriving potential answer candidates. Combined with a strong reward model that selects the right answer out of the many candidate answers, AIMO2-combined could come close to o3-preview medium-compute.
-
The graphs raise further interesting questions that call for continued investigation. For example, the problem "WEIRDY" is notable, as only the fourth-placed winner in AIMO2, sravn, got it right. It remains to be seen whether this is due to randomness during the model run, which may have negatively impacted all the other winning models, or whether other winning models are unable to execute a reasoning pattern that a sizable percentage of the Kaggle submissions were able to perform as well.
-
There seems to be some issues with the training data of o3-preview that make all versions of o3-preview miss the "RUNNER" problem when evaluated pass@1, which NemoSkills, as well as a non-trivial number of Kaggle contestants, were able to solve. However, the high-compute version of o3-preview manages to solve this problem when taking into account the second-ranked answers.
Conclusion & AIMO3
It is fundamental that open-source models are widely available to ensure scientific reproducibility. Our evaluation provides a nuanced understanding of the reasoning performance gap between open-source models and closed models in the context of mathematical reasoning.
In absolute terms, not taking into account limitations arising from compute cost, o3-preview comes close to saturating our benchmark in the high-compute version, even though it is a general model, not optimized for mathematics. This is an impressive achievement, showing better performance than we expected. Taking into account that that model has been improved since we ran our evaluation in March, and that our problems are not publicly available and have long and complex solutions (we refer the reader to our ten publicly released reference problems which were not used for this evaluation), this shows that a noticeable distance persists between state-of-the-art open-source models and state-of-the-art closed-source models in terms of reasoning performance.
When factoring in the compute cost, the gap is significantly smaller. One run of o3-preview in the low-compute version on our 50-problem benchmark averages out to slightly below US$1 per problem. This is higher than running all five winning models on an owned, private 8x H100 box, and roughly comparable to running a single winning model on a commercially rented 8x H100 box; an exact price comparison is difficult to make, but the order of magnitude of cost is similar. The combined score of the original top-five models on AIMO2 is 38/50, trailing the o3-preview low-compute model by five points, which shows that, adjusted solely for compute on 50 problems, reasoning performance is roughly similar.
The AIMO Progress Prize 3 (AIMO3) will launch in Autumn 2025. The difficulty level will increase again, with the problems centred at the International Mathematical Olympiad-level. Full details on the timings, prize pot, and improved competition format will be announced in due course. The AIMO community has been exceptionally lively, and we asked for improvement suggestions. We received many ideas through the Kaggle Discussion forum, which also contains a host of other useful information about open-source training of machine learning models for mathematics – stay tuned for a better competition format!
We will follow up with a technical report on the AIMO2 competition, which includes the information from this blog and provides even more insight into the 50 AIMO2 public leaderboard problems and the performance of the models on them.